引言
Elasticsearch(簡(jiǎn)稱ES)是一個(gè)基于Apache Lucene構(gòu)建的分布式、RESTful風(fēng)格的搜索和分析引擎。它以其高效的全文檢索、近實(shí)時(shí)搜索和強(qiáng)大的分布式能力,在大數(shù)據(jù)存儲(chǔ)、日志分析、企業(yè)搜索等場(chǎng)景中廣泛應(yīng)用。理解ES的數(shù)據(jù)存儲(chǔ)與查詢基本原理,對(duì)于有效利用其數(shù)據(jù)處理和存儲(chǔ)服務(wù)至關(guān)重要。
1. 核心數(shù)據(jù)結(jié)構(gòu)與索引
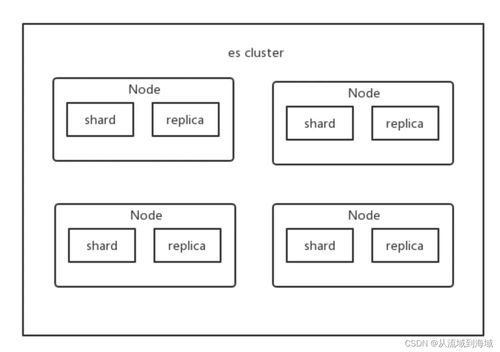
ES的核心概念圍繞“索引”展開。在ES中,一個(gè)索引可以類比為傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)中的一個(gè)數(shù)據(jù)庫(kù)。它包含多個(gè)分片,每個(gè)分片是一個(gè)獨(dú)立的Lucene索引,負(fù)責(zé)存儲(chǔ)數(shù)據(jù)的一部分。
- 文檔:ES中存儲(chǔ)的基本數(shù)據(jù)單元,以JSON格式表示。每個(gè)文檔包含多個(gè)字段。
- 映射:定義文檔的字段類型和屬性,決定了數(shù)據(jù)如何被索引和存儲(chǔ)。例如,文本字段會(huì)進(jìn)行分詞處理,而數(shù)值或日期字段則按原樣存儲(chǔ)。
- 倒排索引:ES查詢高效的核心。它記錄了每個(gè)詞項(xiàng)出現(xiàn)在哪些文檔中,并包含位置等信息。這使得全文檢索可以快速定位包含特定詞匯的文檔,而非逐條掃描。
2. 數(shù)據(jù)寫入與存儲(chǔ)流程
當(dāng)數(shù)據(jù)寫入ES時(shí),會(huì)經(jīng)歷一系列處理步驟:
- 文檔接收:客戶端通過(guò)HTTP REST API發(fā)送JSON文檔到ES集群。
- 路由與分片:ES根據(jù)文檔的ID或路由鍵,通過(guò)哈希算法確定其應(yīng)歸屬的主分片。每個(gè)索引被分成多個(gè)主分片,以實(shí)現(xiàn)水平擴(kuò)展和并行處理。
- 索引處理:文檔到達(dá)目標(biāo)分片后,會(huì)進(jìn)行以下操作:
- 分析:對(duì)文本字段進(jìn)行分詞、歸一化(如轉(zhuǎn)為小寫)、去除停用詞等,生成詞項(xiàng)。
- 構(gòu)建倒排索引:將詞項(xiàng)及其在文檔中的信息添加到倒排索引結(jié)構(gòu)中。
- 刷新與提交:
- 刷新:默認(rèn)每1秒執(zhí)行一次,將內(nèi)存中的索引數(shù)據(jù)寫入文件系統(tǒng)緩存,使新文檔可被搜索(近實(shí)時(shí)性)。
- 提交:定期將多個(gè)段合并,并寫入磁盤持久化,優(yōu)化存儲(chǔ)和查詢性能。
- 副本同步:每個(gè)主分片可以有多個(gè)副本分片。寫入操作首先在主分片上完成,然后異步復(fù)制到副本分片,確保數(shù)據(jù)冗余和高可用性。
3. 數(shù)據(jù)查詢基本原理
ES的查詢過(guò)程涉及多個(gè)階段的協(xié)作,以實(shí)現(xiàn)快速且相關(guān)的搜索結(jié)果。
- 查詢解析:查詢請(qǐng)求(如匹配查詢、范圍查詢等)被解析成查詢DSL(領(lǐng)域特定語(yǔ)言)表示。
- 分發(fā)與執(zhí)行:
- 查詢請(qǐng)求被發(fā)送到協(xié)調(diào)節(jié)點(diǎn),該節(jié)點(diǎn)將查詢轉(zhuǎn)發(fā)給相關(guān)分片(主分片或副本)。
- 每個(gè)分片獨(dú)立執(zhí)行查詢,在本地倒排索引中查找匹配的文檔,并根據(jù)相關(guān)性評(píng)分算法(如TF-IDF、BM25)計(jì)算文檔得分。
- 結(jié)果合并:協(xié)調(diào)節(jié)點(diǎn)收集所有分片的局部結(jié)果,進(jìn)行全局排序、過(guò)濾和聚合,生成最終結(jié)果集。
- 返回結(jié)果:將排序后的文檔(通常包含ID、得分和源數(shù)據(jù))返回給客戶端。
4. 數(shù)據(jù)處理與存儲(chǔ)服務(wù)的優(yōu)化
基于上述原理,ES在數(shù)據(jù)處理和存儲(chǔ)服務(wù)方面提供了多項(xiàng)優(yōu)化特性:
- 近實(shí)時(shí)搜索:通過(guò)定期刷新機(jī)制,數(shù)據(jù)在寫入后約1秒內(nèi)即可被搜索,平衡了性能與實(shí)時(shí)性。
- 分布式架構(gòu):分片和副本機(jī)制支持水平擴(kuò)展,處理海量數(shù)據(jù)和高并發(fā)查詢。
- 聚合分析:支持豐富的聚合功能(如統(tǒng)計(jì)、分組、嵌套聚合),適用于數(shù)據(jù)分析和報(bào)表生成。
- 冷熱數(shù)據(jù)分層:結(jié)合ILM(索引生命周期管理),可將熱數(shù)據(jù)存儲(chǔ)在SSD上以優(yōu)化查詢性能,冷數(shù)據(jù)遷移到HDD以降低成本。
- 數(shù)據(jù)壓縮:使用高效編碼和壓縮算法(如LZ4、DEFLATE)減少存儲(chǔ)空間占用。
5. 應(yīng)用場(chǎng)景與
ES的數(shù)據(jù)存儲(chǔ)與查詢?cè)O(shè)計(jì),使其特別適合以下場(chǎng)景:
- 全文檢索:網(wǎng)站搜索、文檔檢索等,利用倒排索引實(shí)現(xiàn)快速關(guān)鍵詞匹配。
- 日志與指標(biāo)分析:通過(guò)集成如Logstash、Beats等工具,實(shí)現(xiàn)日志的實(shí)時(shí)采集、存儲(chǔ)和可視化分析。
- 商業(yè)智能:結(jié)合Kibana進(jìn)行數(shù)據(jù)探索和儀表板展示,支持復(fù)雜的聚合查詢。
Elasticsearch通過(guò)其獨(dú)特的倒排索引、分布式分片和近實(shí)時(shí)處理機(jī)制,提供了高效、可擴(kuò)展的數(shù)據(jù)處理與存儲(chǔ)服務(wù)。深入理解這些基本原理,有助于用戶更好地設(shè)計(jì)索引、優(yōu)化查詢,并在實(shí)際應(yīng)用中充分發(fā)揮其潛力,滿足多樣化的數(shù)據(jù)管理需求。